4. Django框架之路由详解¶
路由的作用是根据用户的请求(主要包含url和请求方法)调用相应的处理模块。
这个模块是纯粹的Python代码,包含URL模式(简单的正则表达式)到Python函数(你的视图)的简单映射。
具体讲,这个模块就是指的是django项目中的urls.py文件。
4.1. Django如何处理一个请求(有点绕,初学者绕行)¶
当一个用户请求Django站点的一个页面,下面是Django系统决定执行以下Python代码使用的算法:
- Django,确定使用根URLconf模块。通常,这是
ROOT_URLCONF设置的值,但如果放置HttpRequest对象拥有urlconf属性(通过中间件设置),则其值将被替换为ROOT_URLCONF设置。 - Django加载该Python模块并寻找可用的
urlpatterns。它是django.urls.path()和(或)django.urls.re_path()实例的序列(sequence)。 - Django依次匹配每个URL模式,在与请求的URL匹配的第一个模式停下来。
- 一旦有URL匹配成功,Djagno引入并调用相关的视图,这个视图是一个简单的Python函数
(或基于类的视图基于类的视图)。
- 一个
HttpRequest实例。 - 如果匹配的URL返回没有命名组,那么来自正则表达式中的匹配项将作为位置参数提供。
- 关键字参数由路径表达式匹配的任何命名部分组成,并由
django.urls.path()或django.urls.re_path()的可选kwargs参数中指定的任何参数覆盖。
- 一个
- 如果没有URL被匹配,或者匹配过程中出现了异常,Django会调用一个适当的错误处理视图。参加下面的错误处理( 错误处理)。
4.2. Django框架中的两种路由定义方式¶
- django.urls.path()
- django.urls.re_path()
区别:
path: 是定义字符串为url规则
re_path: 可以是字符串或者字符串和正则的组合
path('tuling/', views.tuling), re_path(r'^\w{3}/$',views.tuling2),
下面是对re的一个基础解释,具体可参看前面课程:
# ^ 在正则表达式中 代表 限制开始
# \w 在正则表达式中 代表 单个的 字母/数字/下划线
# {3} 在正则表达式中 代表匹配的次数
# $ 在正则表达式中 代表 限制结尾
# '^\w{3}/$' 就整体代表 字母/数字/下划线 三位组成的字符串以/结尾
# abb/a12/a_11/ 不符合 字符长度不对,开始和结尾不对。
4.3. Django框架中路由详解¶
本实验创建一个django项目v2。
具体创建过程参考上面内容。
4.3.1. 路由的访问方式¶
- 从上往下的逐个匹配,如果匹配到相应的路由,则调用响应处理模块,匹配终止
- 如果最终没有找到相应的匹配,则报错
- 如果由子路由,则匹配到相应的父级路由后,进入子路由重复上面匹配过程
4.3.2. 子路由¶
Django项目同名的文件夹下的urls成为总路由,它负责整个项目的路由分配。
一般使用的时候我们推荐的方式是,项目同名的文件夹下只负责配置,具体业务处理根据不同的业务 设置不同的APP,我们在总路由下,也只是做一个简单的配置就可以,以下代码的含义是, 对所有访问 路由是/tuling/下的所有的访问,都交由tuling的APP的子路由处理:
# 总路由下的代码
from django.contrib import admin
from django.urls import path, include
from tuling import views
urlpatterns = [
# url中包含tuling的请求都有子路由tuling.urls处理
path('tuling/', include("tuling.urls"))
... ...
]
相应的子路由的urls的代码如下:
from django.contrib import admin
from django.urls import path, include
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
# 子路由是sub_tuling的由views下的sub_tuling函数处理
path('sub_tuling/', views.sub_tuling)
]
而我们的访问URL路由如下图所示,主路由从根路由开始查找,当找到tuling/的时候就知道 这个访问应该有tuling APP处理,所以把路由剩下的部分sub_tuling/交给子路由处理,子路由再 根据匹配规则进行处理:
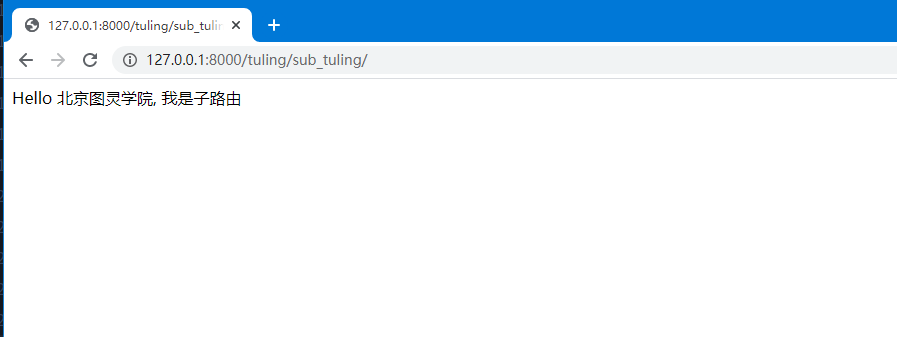
子路由的访问方式类似文件夹,一层一层的访问,子路由就相当于子文件夹。
4.3.3. django.url.path¶
path路由器采用字符串匹配模式,直接匹配用户的字符串。
#此时匹配的url是tuling1,只有找到这个字符串后才调用相应的试图函数进行处理
path('tuling1/', views.tuling1),
4.3.4. django.url.re_path¶
re_path路由是根据正则匹配的方式进行匹配,如果匹配到了就进行处理。
除了这个是使用正则进行匹配外,其余的匹配规则跟path基本一致。
#匹配的内容这部分采用的是正则的写法
re_path(r'^\w{3}/$',views.tuling2),
4.3.5. 关键字参数传递¶
对服务器进行访问的时候有时候需要传入一些内容,路由会根据传入的内容进行匹配,此时可以 把传入的部分url内容当作参数调用试图处理模块。
典型应用如下:
- 麦扣网(www.mycode.wang)是程序员博客网
- 比如我的网址是 www.mycode.wang/blog/liudana
- 而相应的我发的博客的网址可能就是 www.mycode.wang/blog/liudana/221234.html
- 前面blog表示这个是blog的版块
- liudana是某个做着的子url
- 221234是我的某一篇blog的id号码
- 此种情况,如果对每一篇blog都由一个自己的url,进行路由匹配的时候会很多,而且也会很麻烦,所以 可以采用一个办法啊,即把blog的id作为参数传递就可以
使用path可以捕获url中的一部分内容作为视图函数的关键字参数进行传递,也是路由的基本功能。
使用方法为<int:year>, 此时向视图处理函数传递一个叫year的int型的参数。
则上述blog可能的路由就是:
pyth('/blog/liudana/<int:blog_id>/', views.blog),
本代码案例中tuling2和tuling3使用了带参数的路由;
from django.contrib import admin
from django.urls import path, include
#导入tuling APP下的试图
from tuling import views
#导入tuling APP下的路由文件, 作为子路由
from tuling import urls as tu
urlpatterns = [
path('admin/', admin.site.urls),
path('tuling1/', views.tuling1),
path('tuling2/<int:year>', views.tuling2),
path('tuling3/<str:name>', views.tuling3),
path('tuling/', include(tu))
]
4.3.6. path转换器¶
path路由使用过程中,会把传入的内容自动转换成了对应类型的参数,比如<int:year> , 会把
传入的数字自动转换成了整数表示的year参数,其中我们把int叫做path转换器(Path Converter),
jango2默认支持以下5个转化器:
- str: 匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
- int: 匹配正整数,包含0。
- slug: 匹配字母、数字以及横杠、下划线组成的字符串。
- uuid: 匹配格式化的uuid,如 075124d3-6485-412e-a2a8-6c931ea72f00
- path: 匹配任何非空字符串,包含了路径分隔符
如果上述五种转换器还不能满足需求,我们可能需要自己定义自己的转换器。
Path转换器是一个特殊的类,需要满足三点要求:
- regex: 类属性,字符串类型,是匹配内容时候的正则表达式
- to_python(self, value) 方法: value是由类属性 regex 所匹配到的字符串, 返回具体的Python变量值,以供Django传递到对应的视图函数中
- to_url(self, value) 方法: 和 to_python 相反,value是一个具体的Python变量值, 返回其字符串,通常用于url反向引用
可以理解成,一个转换器就是有上述三个属性或者函数的类。
先看看默认的 IntConverter 和 StringConverter 是怎么实现的: 先来看看int和str的转换器的源代码:
class IntConverter:
regex = '[0-9]+'
def to_python(self, value):
return int(value)
def to_url(self, value):
return str(value)
class StringConverter:
regex = '[^/]+'
def to_python(self, value):
return value
def to_url(self, value):
return value
下面我们模仿转换器的源代码自己写一个自己的转换器(源代码:v2/v2/urls.py)。
我们需要一个四位数的年份转换器,用来把用户的输入作为一个四位数的年份,一个要求
是我们只能转换形如19xx的年份,别的不行:
编写自定义的转换器需要两步完成:
编写代码,一般类命名为xxxConverter:
class FourDigitYearConverter: #只能识别19xx这样的年份 regex = '19[0-9]{2}' def to_python(self, value): return int(value) def to_url(self, value): return '%04d' % value
注册, 即使用register_converter 将其注册到URL配置中
from django.urls import path, include, register_converter # 演示的关系,Converter直接写在了路由文件中 # 实际使用时建议放入convertes文件 class FourDigitYearConverter: # 只能识别19xx这样的年份 regex = '19[0-9]{2}' ... ... # 把FourDigitYearConverter注册成Y4这个变量 register_converter(FourDigitYearConverter, 'Y4')
4.3.6.1. 2.re_path 捕获url中的内容作为参数¶
re_path() 中可以使用 (?P<参数名>参数规则) 来捕获URL中的参数
# re_path 捕获url中的内容作为参数
re_path(r'^name/(?P<name>\w{3,8})/$',views.getname),
re_path(r'^(?P<name>\w{3,8})/p/(?P<pid>\d{8})/$',views.getnamepost),
# 非命名参数捕获,这样定义那么对应的视图函数中只要有这个行参就可以
re_path(r'^(\w{3,8})/p/(\d{8})/$',views.gnamep),
4.3.7. 传递额外参数¶
请求的参数不仅仅来自以URL,还可能是我们自己定义的内容。
以下的路由处理,除了把url中的对应年份作为参数year传入视图函数外,还会 额外增加参数name,视图需要同时接收两个参数。
path('tuling6/<int:year>/', views.tuling6, {"name":"北京图灵学院"}),
对应的视图函数为:
def tuling6(r, year, name):
rst = f"Hello, {name}创始于{year}年"
return HttpResponse(rst)
4.3.8. re_path中的参数处理¶
re_path兼容django2版本前的处理方式,路由匹配采用正则来完成,同样也可以处理带参数的 url。
在Python正则表达式中,命名式分组语法为 (?P
需要注意的是,采用re_path的时候,传入的参数是str类型的,如果需要别的类型,需要自己转换。
# path自定义的converter
path('tuling4/<Y4:y>/', views.tuling4),
# 把上述的自定义的converter转变成正
# 正则中的参数处理
# 把19xx的数字传换成参数yy的值传入视图处理函数
re_path('tuling5/(?P<yy>19[0-9]{2})/', views.tuling5),则表达是的参数处理方式
4.3.9. URL反向的解析¶
我们再代码中有时候也会用到相应的路由对应的url,此时如果我们直接把 url写入源代码中,会造成硬编码问题,导致后面代码的维护性通用性都会降低,为了 消除这种情况,我们使用反向解析的url。
对url反向解析本质上是对每一个URL进行命名, 以后再编码代码中使用URL的值, 原则上都应该使用反向解析即可。
我们通过案例来讲解url反向解析。
假如有这样一个URL的规则是解析到显示文章的视图的映射:
# 路由 urls.py
path('get/post/<int:id>/',views.getpost)
# 视图 views.py
def getpost(request,id):
# 通过文章id获取文章数据
# 把文章内容解析到模版中
return HttpResponse(f'{id}:的文章内容。。。')
那么在需要定义链接地址的地方, 如html的a链接中可以直接硬编码的方式定义链接,例如:
<!-- index.html -->
<a href="/get/post/3/">Python3编码规范-硬编码</a>
这样就可以在页面中,通过a链接跳转到对应的文章视图函数中,查看文章的内容。
但是这样做有一个致命的缺陷: 一旦url规则发生变化或url规则较多时,非常容易出错。 假如 把url路由的规则改变了,那么对应的链接就会失效,你能想象你需要更改整个网站中的链接的痛苦场景。
因此,Django的路由可以设置url反向解析来一劳永逸的解决这个问题。
具体步骤是:
在定义对应的路由规则时,只需要给定义的路由设置name关键字参数来表示路由名字
# 在定义路由时,可以指定路由的名字,在使用时通过路由名动态解析路由规则 url path('getpost/<int:id>/',views.getpost,name="home_getpost")
在需要使用url的html页面中可以使用 url标签进行动态的反向解析
<!-- index.html --> <!-- {% url '路由名' 路由捕获参数 %} --> <a href="{% url 'home_getpost' 3 %}">Python3编码规范-反向解析</a>不管你路由规则怎么变化,只要路由名称不变,那么通过反响解析的链接也不需要更改
url反向解析的使用:
- html模版中 可以使用url标签来反向解析, 如上面所示
- 在其他的python代码中 使用 reverse() 方法进行反向解析。django.url.reverse() 示例代码如下:
路由需要使用name参数
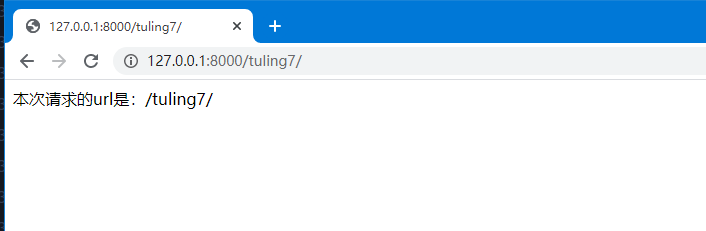
# v2/v2/urls.py ... ... #反向解析 path('tuling7/', views.tuling7, name="TuLing_7"), ... ...
视图处理需要引入
django.urls.reverse()# v2/tuling/views.py ... ... from django.urls import reverse def tuling7(r): rst = "本次请求的url是:{} ".format(reverse("TuLing_7")) return HttpResponse(rst) ... ...
最终结果如下图: